
La statistica è una disciplina fondamentale per la data science, offrendo gli strumenti necessari per analizzare e interpretare i dati.
In questo articolo, esploreremo le statistiche descrittive e la visualizzazione dei dati, due componenti essenziali per qualsiasi data scientist.
Analizzeremo i principali concetti statistici e mostreremo come applicarli utilizzando Python, con esempi reali per facilitare la comprensione.
Breve storia della Statistica
La statistica, come disciplina formale, ha iniziato a svilupparsi nel XVII secolo con i contributi di matematici come Blaise Pascal e Pierre de Fermat.
Durante il XIX e il XX secolo, figure come Karl Pearson e Ronald Fisher hanno ulteriormente sviluppato la statistica, introducendo concetti fondamentali come la regressione, la correlazione e l’analisi della varianza (ANOVA).
Utilizzo della statistica nel Data Science
Nel contesto della data science, la statistica è cruciale per:
- Descrivere i dati: Riassumere grandi set di dati con misure sintetiche.
- Fare inferenze: Generalizzare dai campioni alla popolazione più ampia.
- Identificare pattern: Scoprire tendenze e relazioni nei dati.
- Costruire modelli predittivi: Utilizzare i dati storici per fare previsioni sul futuro.
Statistiche descrittiva, cos’è
Le statistica descrittiva fornisce strumenti per riassumere e descrivere i dati.
I principali concetti includono la media, la mediana, la moda, la varianza e la deviazione standard.
Misure di tendenza centrale
1. Media: La media (o valore medio) è la somma di tutti i valori divisa per il numero totale di valori.
import numpy as np
dati = [1, 2, 3, 4, 5]
media = np.mean(dati)
print(f"Media: {media}") # Output: Media: 3.02. Mediana: La mediana è il valore centrale di un set di dati ordinato.
mediana = np.median(dati)
print(f"Mediana: {mediana}") # Output: Mediana: 3.03. Moda: La moda è il valore che appare con maggiore frequenza in un set di dati.
from scipy import stats
moda = stats.mode(dati)
print(f"Moda: {moda.mode}") # Output: Moda: 1Misure di dispersione
1. Varianza: La varianza misura la dispersione dei dati rispetto alla media.
varianza = np.var(dati)
print(f"Varianza: {varianza}")
# Output: Varianza: 2.02. Deviazione Standard: La deviazione standard è la radice quadrata della varianza e fornisce una misura della dispersione dei dati.
deviazione_standard = np.std(dati)
print(f"Deviazione Standard: {deviazione_standard}") # Output: Deviazione Standard: 1.4142135623730951Esempio statistica descrittiva applicato nel Data Science
Supponiamo di essere un data scientist che lavora per una catena di negozi al dettaglio. Vogliamo analizzare le vendite settimanali di uno dei nostri negozi per capire meglio la performance e identificare eventuali problemi o opportunità.
Dati di Vendita Settimanali (in migliaia di euro):
vendite = [12, 15, 14, 17, 19, 20, 18]
Calcolo delle Misure di Tendenza Centrale e Dispersione:
import numpy as np
from scipy import stats
vendite = [12, 15, 14, 17, 19, 20, 18]
# Media
media_vendite = np.mean(vendite)
print(f"Media delle vendite: {media_vendite:.2f} migliaia di euro")
# Mediana
mediana_vendite = np.median(vendite)
print(f"Mediana delle vendite: {mediana_vendite:.2f} migliaia di euro")
# Moda
moda_vendite = stats.mode(vendite)
# Accedere correttamente all'attributo mode
print(f"Moda delle vendite: {moda_vendite.mode} migliaia di euro")
# Varianza
varianza_vendite = np.var(vendite)
print(f"Varianza delle vendite: {varianza_vendite:.2f}")
# Deviazione Standard
deviazione_standard_vendite = np.std(vendite)
print(f"Deviazione standard delle vendite: {deviazione_standard_vendite:.2f}")
Visualizzazione dei dati con Python
La visualizzazione dei dati è cruciale per comunicare insight e pattern in modo efficace. Alcuni degli strumenti di visualizzazione più comuni includono gli istogrammi, gli scatter plot e i box plot.
Istogrammi
Gli istogrammi mostrano la distribuzione di un set di dati raggruppando i valori in intervalli.
import matplotlib.pyplot as plt
plt.hist(vendite, bins=5, edgecolor='black')
plt.title("Istogramma delle Vendite Settimanali")
plt.xlabel("Vendite (migliaia di euro)")
plt.ylabel("Frequenza")
plt.show()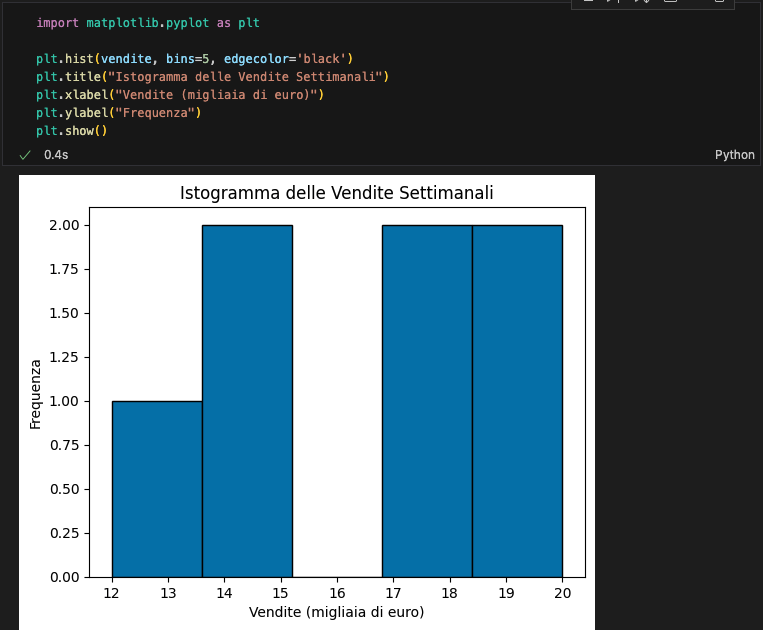
Scatter Plot
Gli scatter plot mostrano la relazione tra due variabili
giorni = list(range(1, 8))
plt.scatter(giorni, vendite)
plt.title("Scatter Plot delle Vendite Settimanali")
plt.xlabel("Giorni")
plt.ylabel("Vendite (migliaia di euro)")
plt.show()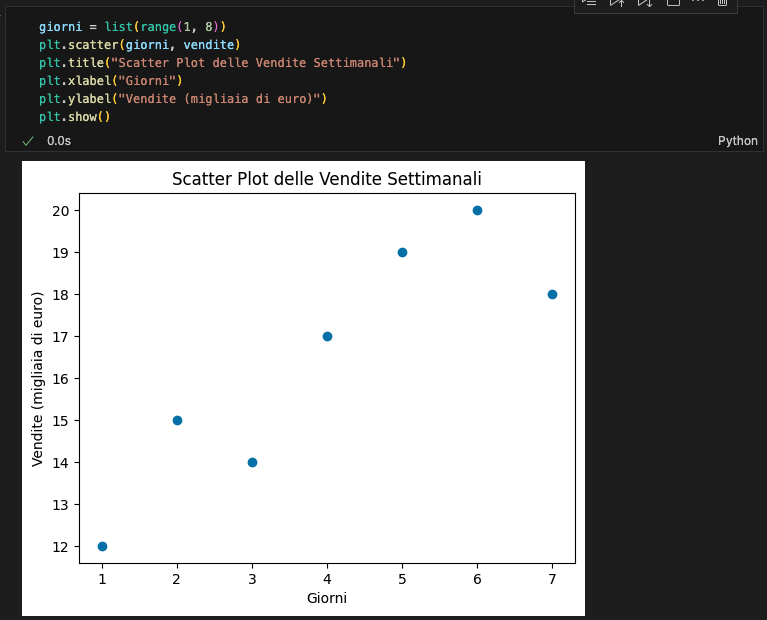
Box Plot
I box plot visualizzano la distribuzione dei dati mostrando mediana, quartili e valori anomali.
plt.boxplot(vendite)
plt.title("Box Plot delle Vendite Settimanali")
plt.ylabel("Vendite (migliaia di euro)")
plt.show()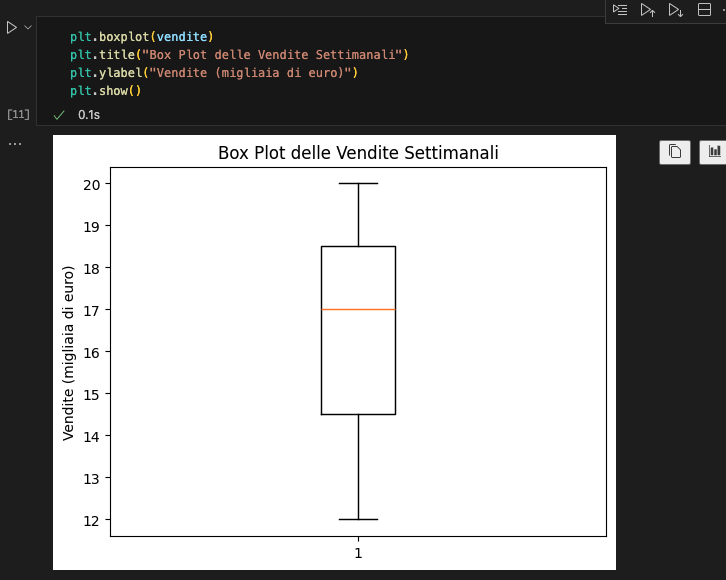
Conclusione statistica descrittiva data science
Le statistiche descrittive e la visualizzazione dei dati sono fondamentali per qualsiasi data scientist. Questi strumenti consentono di riassumere, comprendere e comunicare grandi set di dati in modo efficace.
Utilizzando Python, possiamo facilmente calcolare queste statistiche e creare visualizzazioni che aiutano a prendere decisioni informate basate sui dati.
La combinazione di competenze statistiche e abilità di programmazione è essenziale per eccellere nel campo della data science.
Lascia un commento